使用工具: x64dbg, IDA, Python bitstring, 010editor
程序用了Team Jellyfish的GPU RAT PoC:https://web.archive.org/web/20171224092129/https://github.com/x0r1/WIN_JELLY https://github.com/vineetgaurav/WIN_JELLY/blob/master/jellycuda/jellycuda.c nvcuda.dll应该是模拟显存用的,建议题目说清楚是模拟显存,盯了一会nvcuda.dll看了后面题目才发现是要生成显存文件后再运行一次程序。
53、程序在运行时会尝试加载哪个本地库以使用CUDA接口?(答案格式:全小写,如xxx.dll)( )
答案:nvcuda.dll
CUDA的库那肯定是nvcuda.dll呀
54、程序在运行时成功加载了几个CUDA接口函数?(答案格式:仅数字)( )
答案:8
看代码是加载了8个函数,不过题目问的是成功加载的数量,可以调试看一下是否都加载成功,设置这两个GetProcAddress断点看返回值即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 hModule = LoadLibraryA("nvcuda.dll" ); if ( !hModule ) return 0 ; v7 = &cuCtxCreateV2; for ( i = 0 ; (&Source)[i]; ++i ) { ProcAddress = GetProcAddress(hModule, (&Source)[i]); *v7 = ProcAddress; if ( !*v7 ) { strcpy (Destination, (&Source)[i]); v4 = strstr (Destination, "_v2" ); if ( v4 ) { *v4 = 0 ; v2 = GetProcAddress(hModule, Destination); *v7 = v2; } } if ( !*v7 ) { FreeLibrary(hModule); return 0 ; } ++v7; } return hModule; }
1 2 3 4 5 6 7 8 .data:00404020 Source dd offset aCuctxcreateV2 ; "cuCtxCreate_v2" .data:00404024 dd offset aCudeviceget ; "cuDeviceGet" .data:00404028 dd offset aCudevicegetcou ; "cuDeviceGetCount" .data:0040402C dd offset aCuinit ; "cuInit" .data:00404030 dd offset aCumemallocV2 ; "cuMemAlloc_v2" .data:00404034 dd offset aCumemcpydtohV2 ; "cuMemcpyDtoH_v2" .data:00404038 dd offset aCumemcpyhtodV2 ; "cuMemcpyHtoD_v2" .data:0040403C dd offset aCumemfreeV2 ; "cuMemFree_v2"
加载后的函数指针依次写入了v7开始的几个DWORD,可以重命名一下方便分析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 .bss:00407040 ; int (__stdcall *cuCtxCreateV2)(_DWORD, _DWORD, _DWORD) .bss:00407040 cuCtxCreateV2 dd ? ; DATA XREF: sub_401FFA:loc_402027↑o .bss:00407040 ; sub_4026F8+90↑r .bss:00407044 ; int (__stdcall *cuDeviceGet)(_DWORD, _DWORD) .bss:00407044 cuDeviceGet dd ? ; DATA XREF: sub_4026F8+72↑r .bss:00407048 ; int (__stdcall *cuDeviceGetCount)(_DWORD) .bss:00407048 cuDeviceGetCount dd ? ; DATA XREF: sub_4026F8+57↑r .bss:0040704C ; int (__stdcall *cuInit)(_DWORD) .bss:0040704C cuInit dd ? ; DATA XREF: sub_4026F8:loc_40273A↑r .bss:00407050 ; int (__stdcall *cuMemAlloc_v2)(_DWORD, _DWORD) .bss:00407050 cuMemAlloc_v2 dd ? ; DATA XREF: sub_401500:loc_401510↑r .bss:00407054 ; int (__stdcall *cuMemcpyDtoH_v2)(_DWORD, _DWORD, _DWORD) .bss:00407054 cuMemcpyDtoH_v2 dd ? ; DATA XREF: sub_401B26:loc_401BFE↑r .bss:00407058 ; int (__stdcall *cuMemcpyHtoD_v2)(_DWORD, _DWORD, _DWORD) .bss:00407058 cuMemcpyHtoD_v2 dd ? ; DATA XREF: sub_4023EF+22E↑r .bss:0040705C ; int (__stdcall *cuMemFree_v2)(_DWORD) .bss:0040705C cuMemFree_v2 dd ? ; DATA XREF: sub_401B26+C3↑r
55、程序在写入木马时,会进行内存分配,请给出内存分配失败时,每次尝试的分配值(按从大到小顺序,以十六进制字符串数组形式表示)。(答案格式:0x20、0x10)( )
答案:0x10000000、0x4000000
根据cuMemAlloc_v2的调用找到内存分配的逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 v8 = sub_401500(0x10000000u , 0x4000000u , dwBytes); if ( !v8 ) return MessageBoxA(0 , "Failed to allocate GPU memory." , "err" , 0x40010u ); int __cdecl sub_401500 (unsigned int a1, unsigned int a2, unsigned int *a3) { _DWORD v4[3 ]; for ( *a3 = a1; *a3 >= a2; *a3 >>= 2 ) { if ( !cuMemAlloc_v2(v4, *a3) ) return v4[0 ]; } *a3 = 0 ; return 0 ; }
传入sub_401500的参数为分配显存的上下限,每次分配失败会将请求大小右移两位。上限0x10000000右移两位即为下限0x4000000,不会有其他尝试的大小,所以答案是0x10000000、0x4000000。
56、程序在写入木马过程中,会对木马内容计算校验值,请还原该校验函数的实现,并给出封装文件若为nvcuda.dll时的校验值。(答案格式:0x8d)( )
答案:0x3fd290fc
写入木马的流程为,读取dll,拼一个12字节的头,将头和dll写入内存,调用cuMemcpyHtoD_v2从内存复制到显存。12字节数据结构如下。
1 2 3 4 5 6 Src = v9; *v9 = 0x5DAB355 ; *(Src + 1 ) = nNumberOfBytesToRead; v3 = sub_401FAE(Src + 12 , nNumberOfBytesToRead); *(Src + 2 ) = v3; nNumberOfBytesToRead += 12 ;
显然sub_401FAE应该就是要找到校验值算法。
1 2 3 4 5 6 7 8 9 unsigned int __cdecl sub_401FAE (unsigned __int8 *a1, int a2) { unsigned __int8 *v2; unsigned int i; for ( i = 0 ; a2--; i = rotr(i ^ *v2, 8 ) ) v2 = a1++; return i; }
用bitstring的ror实现一下算法即可。
1 2 3 4 5 6 7 8 with open (r"nvcuda.dll" , "rb" ) as f: data = f.read() from bitstring import BitArrayi = BitArray(uint=0 , length=32 ) for byte in data: i.uint ^= byte i.ror(8 ) print (i)
这题还有一个办法,校验值算法只涉及文件内容,文件名不参与,将nvcuda.dll改名为jellydll.dll,运行程序,生成的内容中可以找到校验值。
1 2 3 4 00000000 55 b3 da 05 00 68 11 00 fc 90 d2 3f 4d 5a 90 00 |U....h.....?MZ..| 00000010 03 00 00 00 04 00 00 00 ff ff 00 00 b8 00 00 00 |................| 00000020 00 00 00 00 40 00 00 00 00 00 00 00 00 00 00 00 |....@...........| 00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
57、程序会喷射大量自定义数据块到RAM中,随后将该缓冲一次性拷入GPU显存。请计算在理想的最大可用空间下该程序能够喷射多少个完整数据块?(答案格式:仅数字)( )
答案:24938
已知一个数据块为12字节头加jellydll.dll的内容,按最大可能申请的显存除一个数据块的大小即可算出。
58、请从程序首次运行后生成的转储文件中,找到被修改过的数据块,提取该数据块的文件内容,并计算文件的MD5值。(答案格式:字母小写)( )
答案:b60d71b5ab26c806049f0c225a9480f6
其实比赛的时候是先做的这个题目,知道这个文件的结构能更快看懂上面的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from collections import Counterimport hashlibwith open (r"sim_gpu_10000000.bin" , 'rb' ) as f: mem = f.read() blk_len = 10752 + 12 blk_count = len (mem) // blk_len blks = [mem[x*blk_len + 12 : (x+1 )*blk_len] for x in range (blk_count)] for x, c in Counter(blks).items(): if c == 1 : print (hashlib.md5(x).digest().hex ())
1 b60d71b5ab26c806049f0c225a9480f6
59、请从转储文件中提取并分析一个未被修改的PE文件,确定Entry Point在该文件中的准确位置,并读取从该位置起连续16字节机器码?(答案格式:1A2B3C···4D5E)( )
答案:5589E583EC045356578B5D088B750C8B
未被修改的文件就是jellydll.dll,DllEntryPoint的偏移是0x540,读取后面的16字节即可。
60、该程序会尝试从显存中读取木马并完成手工加载,在加载过程中会调用系统函数以刷新进程的指令缓存。请写出被调用的函数名。(答案格式:按实际函数名大小写填写)( )
答案:NtFlushInstructionCache
可以直接盯出来,导入函数没有看到刷新指令缓存的函数,字符串里很明显有一个NtFlushInstructionCache。或者通过查找GetProcAddress,GetModuleHandle,LoadLibrary等函数的调用也可以找到。
61、程序在手工加载木马时会重建导入表,请跟踪“按名称导入函数地址”分支,获取该过程中出现的全部函数名并统计数量。(答案格式:仅数字)( )
答案:27
根据上面一题函数的调用能直接找到加载PE文件的位置。
首先是加载PE头,解析PE头,分配内存,写入数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 v17 = *(a1 + 0x3C ) + a1; v16 = VirtualAlloc(0 , *(v17 + 0x50 ), 0x3000u , PAGE_EXECUTE_READWRITE); v29 = *(v17 + 0x54 ); v26 = a1; for ( i = v16; v29--; ++i ){ v1 = v26++; v2 = i; *v2 = *v1; }
接着加载PE节,还是解析头数据,依次读取节数据写入内存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 v22 = (v17 + 0x18 + *(v17 + 0x14 )); v30 = *(v17 + 6 ); while ( v30-- ){ v25 = &v16[v22[3 ]]; v27 = (v22[5 ] + a1); v28 = v22[4 ]; while ( v28-- ) { v4 = v27++; v5 = v25++; *v5 = *v4; } v22 += 10 ; }
接着处理导入表,题目刚好问到了几个按名称导入,这里看没有其他特殊条件,按导入表全都导入了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 if ( *(v17 + 0x84 ) ) { for ( j = &v16[*(v17 + 0x80 )]; *(j + 3 ); j += 20 ) { hModule = LoadLibraryA(&v16[*(j + 3 )]); v19 = &v16[*j]; for ( k = &v16[*(j + 4 )]; *k; ++k ) { if ( v19 && *v19 < 0 ) { v14 = hModule + *(hModule + *(hModule + 15 ) + 120 ); *k = (hModule + *(hModule + 4 * (*v19 - *(v14 + 4 )) + *(v14 + 7 ))); } else { *k = GetProcAddress(hModule, &v16[*k + 2 ]); } if ( v19 ) ++v19; } } }
直接看jellydll.dll的导入表,统计一下27个都是按名称导入。
62、程序在手工加载内存映像时,会遍历其基址重定位表并对表中标记的内存地址执行修正,请提交重定位循环过程中,第二次实际发生写操作的写后值地址对应的内容。(答案格式:按实际值填写)( )
答案:There’s A Rat In My GPU What I’m A Gonna Do?
继续看加载PE文件的代码,最后是处理重定位表,看起来就是依次处理的。
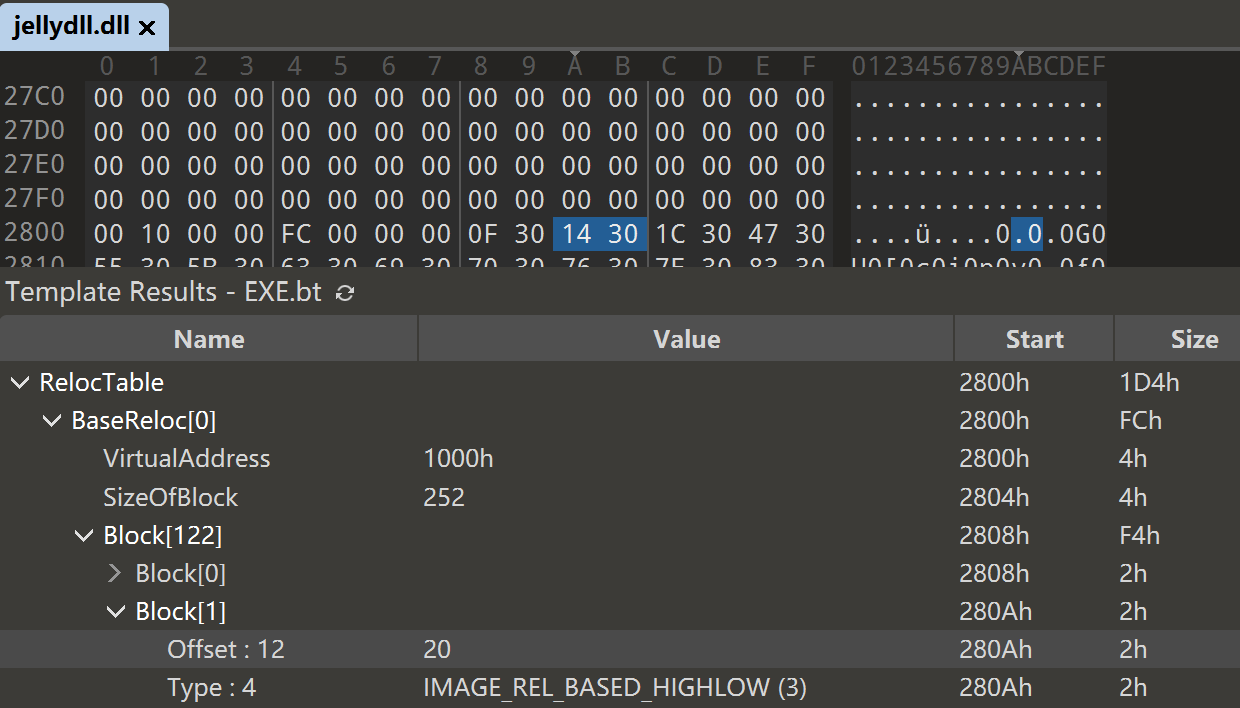
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 if ( *(v17 + 0xA4 ) ) { v13 = &v16[-*(v17 + 0x34 )]; for ( m = &v16[*(v17 + 0xA0 )]; *(m + 1 ); m += *(m + 1 ) ) { v12 = &v16[*m]; v31 = (*(m + 1 ) - 8 ) >> 1 ; for ( n = m + 8 ; v31--; n = (n + 2 ) ) { switch ( *(n + 1 ) & 0xF0 ) { case 0xA0 : *&v12[*n & 0xFFF ] += v13; break ; case 0x30 : *&v12[*n & 0xFFF ] += v13; break ; case 0x10 : *&v12[*n & 0xFFF ] += HIWORD(v13); break ; case 0x20 : *&v12[*n & 0xFFF ] += v13; break ; } } } }
直接010editor看下重定位表,第二个写入操作对应加载地址+0x1000_20。0x10001014,指向0x10003014。
1 2 3 10001000 8B 44 24 08 83 F8 01 75 19 68 40 00 04 00 68 00 10001010 30 00 10 68 14 30 00 10 6A 00 FF 15 B0 40 00 10 10001020 EB E7 31 C0 40 C2 0C 00 CC CC CC CC CC CC CC CC
对应位置是一个字符串
1 2 3 4 5 10003000 3C 3C 50 65 72 73 69 73 74 65 6E 74 20 45 76 69 <<Persistent Evi 10003010 6C 3E 3E 00 54 68 65 72 65 27 73 20 41 20 52 61 l>>.There's A Ra 10003020 74 20 49 6E 20 4D 79 20 47 50 55 20 57 68 61 74 t In My GPU What 10003030 20 49 27 6D 20 41 20 47 6F 6E 6E 61 20 44 6F 3F I'm A Gonna Do? 10003040 00 00 00 00 00 00 00 00 00 00 00 00 08 00 00 00 ................
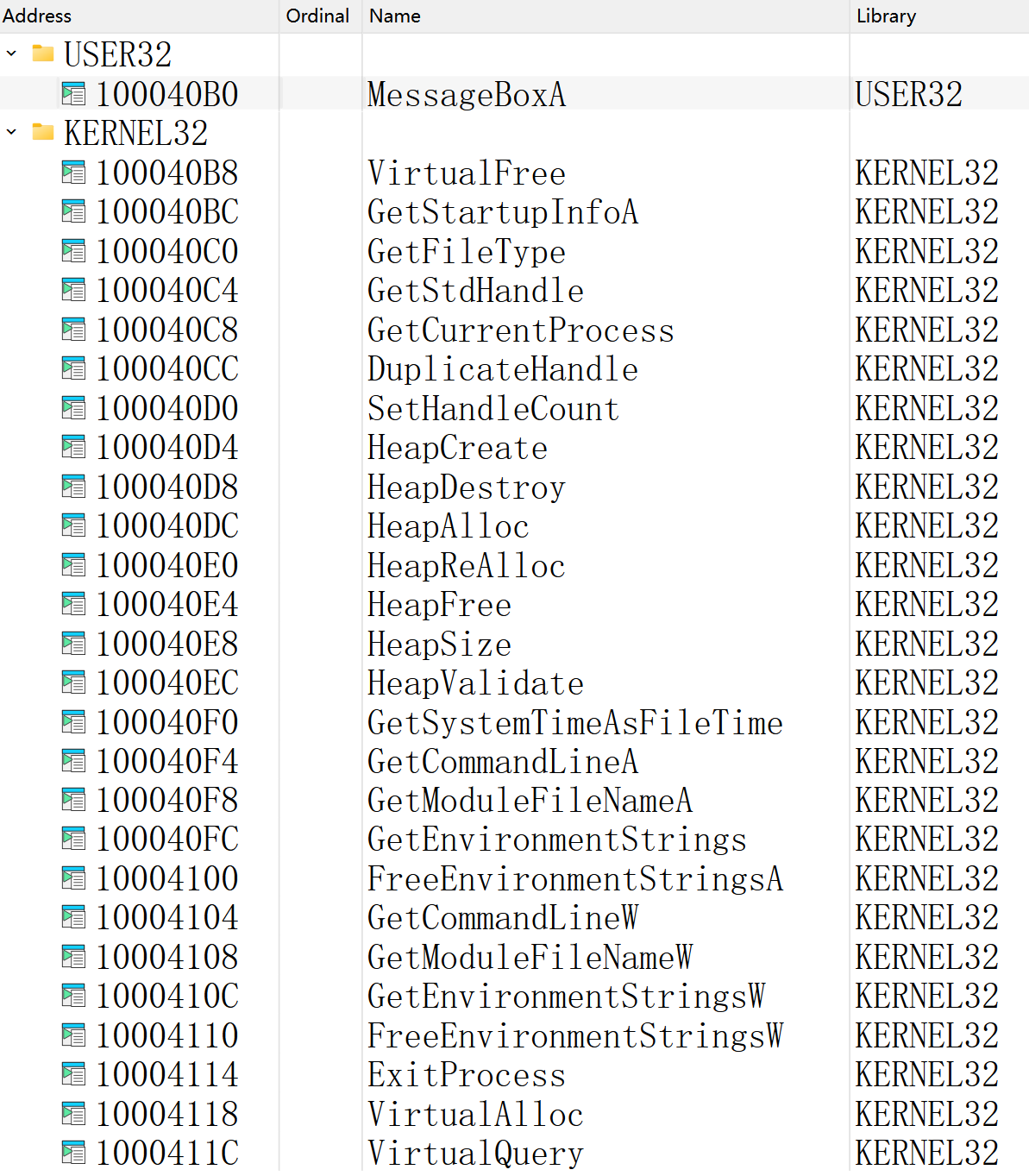
 。打开看了眼导出函数确实有CUDA的那些接口。
。打开看了眼导出函数确实有CUDA的那些接口。